分布式一致性算法
Paxos算法
Google Chubby 的作者 Mike Burrows 说过:这个世界上只有一种一致性算法,那就是 Paxos,其它算法都是残次品
分布式系统中的节点通信存在两种模型:共享内存和消息传递
基于消息传递通信模型的分布式系统,不可避免会发生进程变慢被杀死、消息延迟、丢失、重复等问题
Paxos 是一种基于消息传递且具有高度容错性的一致性算法(即在以上异常的情况下,仍能保持一致性的协议)
在 Paxos 中,分以下三种角色:
- Proposer:提议者,用来发出提案 proposal(提案信息包括提案编号 proposal id 和提议的值 value)
- Acceptor:接受者,参与决策,可以接受或拒绝提案(当提案被超过半数的 Acceptor 接受后,即为被批准)
- Learner:学习者,不参与决策,只学习被选定的提案
换句话说,Paxos 算法就跟议会制一样,少数服从多数(即超过半数)
一个分布式算法有两个最重要的属性:活性(liveness)和安全性(Safely)
简单来说,liveness 是指那些最终一定会发生的事情,Safely 是指那些需要保证永远都不会发生的事情
而 Paxos 算法的 liveness 就体现在:保证最终有一个提案会被选定
Safety 则是这么约束的:
- 决议(value)只有在被 proposer 提出后才能被批准
- 在一次 Paxos 算法的执行实例中(即一次投票过程中),只批准(chose)一个 value
- learner 只能获得被批准(chosen)的 value
liveness和 Safety 组合的结果就是:最终有且只有一个被提出的提案被选定
上面说的是原始的 Paxos 算法(Basic-Paxos),它只能对一个 value 形成决议
实际应用中几乎都需要连续确定多个值,而且希望效率更高,于是有了 Multi-Paxos
其实 Basic-Paxos 也只是一个逻辑概念,落地还是挺困难的
实际中,所有的 Acceptor 都可以成为 Proposer(即都可以发起投票),甚至会出现两个 Proposer 同时发起一个相同的提案
这时怎么确保提案的发起和执行是有顺序的呢?(这是分布式场景中的一个尖锐问题:缺乏全局时钟,也就是无法保证全局顺序)
下文提到的 ZooKeeper 就解决了这个问题
zk 虽然也用了类似概念,不过它对 Paxos 做了一个工业实践:基于 multi-paxos 算法做了改进
zk 构造了 leader-follower 模式,即映射到 zk 集群时,proposer 对应的就是 leader,acceptor 对应 follower,learner 对应 observer
即只有 leader 才能发起提案,follower 参与投票,observer 则被动接受(这里 leader 存在单点故障,所以又提供了 leader 选举机制)
Raft算法
它跟 ZAB 协议基本很相似,这是一个便于理解该算法的在线动画:http://thesecretlivesofdata.com/raft/
ZAB协议
zk 基于 multi-paxos 提供了 ZAB(Zookeeper Atomic Broadcast)协议
ZAB 协议需要确保那些已经在 leader 服务器上提交的事务最终被所有服务器都提交
ZAB 协议需要确保丢弃那些只在 leader 服务器上被提出的事务
如果让 leader 选举算法能够保证新选举出来的 leader 服务器拥有集群中所有机器最高事务编号(ZXID)的事务 proposal
那么就可以保证这个新选举出来的 leader 一定具有所有已经提交的提案
ZAB 两种基本的模式:崩溃恢复和消息广播
zk 的底层工作机制,就是依靠 ZAB 实现的(实现崩溃恢复和消息广播两个主要功能)
补充:关于拜占庭将军问题,严格来说,Paxos 没有解决,但是 ZAB 解决了(区块链也解决了)
抽屉原理
也叫狄利克雷抽屉原理(又名鸽巢原理、鸽笼原理)
它有两种简单的表述法:
- 若有 n 个笼子和 n+1 只鸽子,所有的鸽子都被关在鸽笼里,那么至少有 1 个笼子有至少 2 只鸽子
- 若有 n 个笼子和 kn+1 只鸽子,所有的鸽子都被关在鸽笼里,那么至少有 1 个笼子有至少 k+1 只鸽子
我们对它变种一下
2 个抽屉,一个放了 2 个红苹果,一个放了 2 个青苹果。我们取出 3 个苹果,无论怎么取都至少有 1 个是红苹果
再引申一步,我们把红苹果看成更新了的有效数据,青苹果看成未更新的数据
也就是说不需要更新全部数据(并非全部是红苹果)就可以得到有效数据,当然我们需要读取多个副本完成(取出多个苹果)
换句话说,比如有一条数据,往 5 个节点里写入,只要有至少 3 个节点写入成功,我们就认为是写入成功了
读取时至少读取 3 个节点的数据,就一定能获取到刚才写入的最新的数据
这就很像 Quorum 机制了
Quorum机制
Quorum 机制是分布式场景中常用的,用来保证数据安全,并且在分布式环境中实现最终一致性的投票算法
这种算法的主要原理来源于抽屉原理,它最大的优势是既能实现强一致性,而且还能自定义一致性级别
它有 N、W、R 的三个概念:
- N:复制的节点数,即一份数据被保存的副本数
- W:写操作成功的节点数,即每次数据写入写成功的副本数(W 小于等于 N)
- R:读操作获取最新版本数据所需的最小节点数,即每次读取成功至少需要读取的副本数
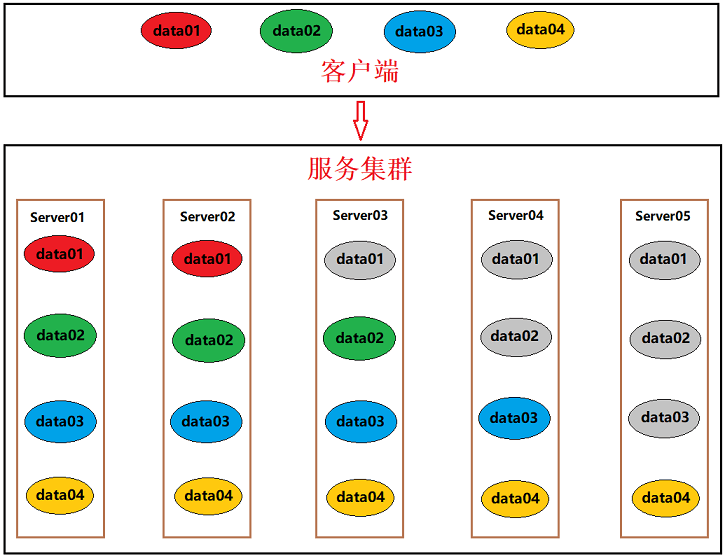
如图所示:客户端写入 data01、data02、data03、data04 四条数据
分别写入成功副本数为 2、3、4、5(有颜色代表写入成功,灰色代表仍为旧版本数据)
此时如果想要读取到这四条数据,则分别需要读取的副本数至少为 4、3、2、1
总结:只要保证 W + R > N 就一定能读取到最新数据(数据一致性级别完全可以根据读写副本数的约束来达到强一致性)
当 N 已经固定的前提下,我们来看以下三种情况:
- W=1,R=N(Write Once Read All)
分布式环境中,只写一份数据,那么读时,就必须读取所有节点才能得到最新数据(写高效,但读效率低) - R=1,W=N(Read Only Write All)
分布式环境中,所有节点都同步完毕才能读,故读任意一个节点就能得到最新数据(读高效,但写效率低) - W=Q,R=Q(Q=N/2+1)
分布式环境中,写超过半数节点,那么读也超过半数节点,使得读写性能平衡(ZooKeeper就是这么干的)
CAP和BASE理论
CAP理论:一个分布式系统不可能同时满足 C、A、P 三个需求
- C:Consistency,强一致性(分布式环境中多个数据副本保持一致)
- A:Availability,高可用性(服务一直可用,用户的每个请求都能在有限时间内返回成功或失败)
- P:PartitionTolerance,分区容错性(网络分区或故障时,依然能够读取到最新数据,并保证服务可用)
网络分区:由于网络失败或延迟导致一部分节点与大部队失去联系,这一部分节点组成了一个小集群
这个小集群也会进行选举,最终就会出现一个带 leader 的小集群,这样一个集群就变成了两个集群
也就形成了网络分区(俗称脑裂),这种局部小集群就会引发各种数据一致性、数据超时等问题
既然三个不能同时满足,那就三选二
- 放弃 P:这就等于放弃了分布式,变成了单机环境(MySQL 就是放弃了 P),所以分布式系统都会保证 P
- 放弃 A:网络分区或其他故障时,服务需要等待一段时间,等待时间内无法对外提供服务,即服务不可用
- 放弃 C:实际是指放弃数据的强一致性,而保留最终一致性,具体多久达到数据同步取决于存储系统的设计
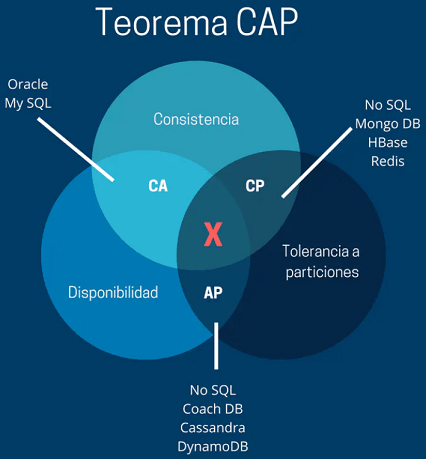
- 对于单机软件,因为不用考虑 P,所以肯定是 CA 型,比如 MySQL
- 对于分布式软件,因为一定会考虑 P,所以只能在 A 和 C 之间权衡,做到服务基本可用,并且数据最终一致性即可
所以产生了 BASE 理论:即使无法做到强一致性,但每个应用可以根据自身业务特点,采用适当的方式来使系统达到最终一致性
- Basically Availiable(基本可用):分布式系统出现故障时,允许损失部分可用性,即保证核心可用
- Soft State(软状态):允许系统存在中间状态,而该中间状态不会影响系统整体可用性
分布式存储中一般一份数据至少会有三个副本,允许副本同步的延迟就是软状态的体现 - Eventually Consistent(最终一致):系统中的所有数据副本经过一定时间后,最终能够达到一致的状态
注意:ACID 和 BASE 代表两种截然相反的设计理念,ACID 注重一致性,是传统关系型数据库的设计思路,BASE 关注高可用性