常见的主流消息队列有以下三款,各自定位也有所不同
- RocketMQ:高性能可靠消息传输
- RabbitMQ:可靠消息传输
- Kafka:系统间的数据流通道(海量数据通过它走通道,比如大数据日志分析,要的就是大量数据的吞吐量)
可以看出:
RocketMQ 和 RabbitMQ 是扛业务流量的,属于OLTP(在线事务处理)
Kafka 偏重数据分析领域,属于OLAP(在线分析处理)
三者的区别,可以这样看:
支持分布式则说明扩展能力好,扩展能力好就能存很多消息,能存的消息多则表示堆积能力好
堆积能力好就能更好的实现削峰填谷(即把请求先缓存在MQ,再慢慢消费,它考验的是 MQ 的堆积能力)
| RocketMQ | RabbitMQ | Kafka | |
|---|---|---|---|
| 数据可靠性 | 高 | 高 | 高 |
| 性能 | 高 | 中 | 非常高 |
| 可用性 | 分布式、主从 | 主从 | 分布式、主从 |
| 堆积能力 | 非常好 | 一般 | 非常好 |
| 延时消息 | 只支持特定Level | 死信队列实现 | 不支持 |
| 事务消息 | 支持 | 不支持 | 不支持 |
| 消息过滤 | 支持 | 不支持 | 支持 |
| 消息查询 | 支持 | 不支持 | 不支持 |
| 批量发送 | 不支持 | 不支持 | 支持 |
| 消费失败重试 | 支持 | 支持 | 不支持 |
高可用
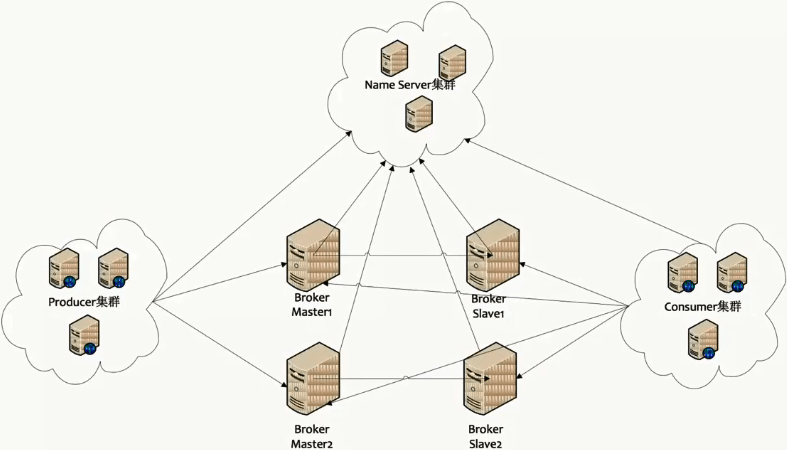
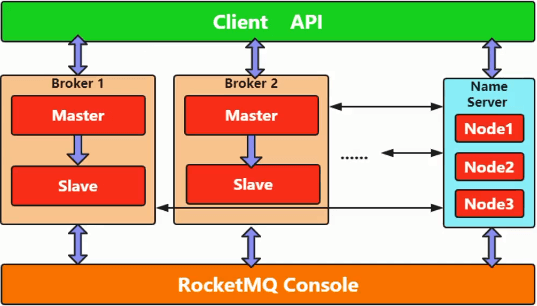
上面是 RocketMQ 的拓扑图和架构图,可以看出,它主要有四个结构:
- NameServer:集群管理
- Broker:存储消息
- Producer:生产者
- Consumer:消费者
其特点如下:
- 每组Broker都是主从部署的,且都会注册自身信息到nameserver
- 每组Broker之间是没有数据同步的(即各个master之间都是独立的)
- 消费消息时,consumer会从nameserver获取topic所在的broker信息,然后建立broker连接,消费消息
- 生产消息时,producer会从nameserver获取可以存储topic的borker信息,然后建立broker连接,投递消息
- producer只会把消息投递到主broker(不会投递到从),而consumer则主从都会去消费(这是高可用的一个手段)
- nameserver集群的各个节点之间相互独立,且无任何的数据通信(它们并不知道彼此的存在)
所以broker在注册时要注册到nameserver的所有节点上,不过nameserver节点很少,再加上还有hearbeat
即便注册失败,还会通过心跳不停的注册来保证nameserver的数据一致性(所以它的节点很快就对齐了)
同样,在做服务发现时,随便连到某一个节点上就可以找到broker了
虽然nameserver集群的实现方式有点偷懒,但broker节点的变化频率并不高,所以这并不会消耗过多的资源
而其分布式就体现在:可以很方便的扩展出一组Broker,然后注册到NameServer
所以说它的堆积能力强就是这个原因(现有的Broker写满了,可以很方便的扩出一组来,扩展性非常好)
可靠性
数据可靠,无非就是说数据不丢
这通常要从两个角度来看:固化(即刷盘,保证本地的数据可靠)和同步(即broker的主从部署,避免单点)
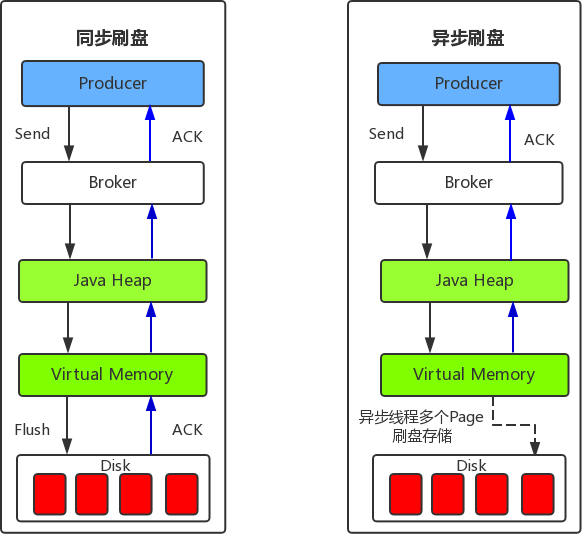
固化方式有两种:
- 同步刷盘:性能低,可靠性高
消息到达broker后,就先写到磁盘上,然后才会返回给producer说消息发送成功 - 异步刷盘:性能高,可靠性低
消息到达broker后,先在缓冲区攒着,然后直接返回给producer说消息发送成功
具体刷盘的动作,是由异步线程在触发了某个阈值之后,再把缓冲区数据写到磁盘
这个阈值一般就是时间和空间(每隔多长时间写一次,空间达到多少写一次)
而丢数据的话,最多也就是丢两次刷盘之间的数据,但是性能高
通过刷盘,保证了本地的数据的可靠,但这还不够,因为分布式系统,就要避免单点
现在主库的数据可靠了,那从库呢(或者说多副本)?
所以要做到一致性写入,就得来看一下数据同步的方式
同步方式也有两种:
- 同步双写:性能低,可靠性高(比如master挂了,没关系,slave有全量消息,能保证被消费)
- 异步复制:性能高,可靠性低
实际部署时,除了根据数据一致性的要求来选择不同的固化和同步方式外,还要考虑机柜
部署这种存储产品时,两台机器都不会放到同一个机柜里面,而是各自独立放在不同的机柜
因为机柜同时掉电的概率太低了,这就等于是间接的保证了可靠性(也就没必要非得同步刷盘同步双写了)
实际生产环境用的异步写更多一些
可用性
这里有一个很重要点:broker主从模式如果master宕机,那么broker就会变成可读不可写的状态
这个特性能保证mstaer剩余未消费的消息,通过slave得到消费(消费的偏移量也会同步到slave)
对于未同步到slave的消息,如果此时broker可写的话,那么这些消息就会被跳过,就会造成它丢了
所以此时要求slave不可写,除非我们人为的把slave提升成master
对于broker的集群搭建方式,有以下不同:
- 单master模式(相当于线下的测试环境,它没什么可用性,挂了就挂了)
- 多master模式(可用性稍好些,但若挂了一个master,里面数据容易丢,所以这个模式意义不大)
- 多master多slave模式(具体固化和同步方式,根据实际情况选择)
消息存储
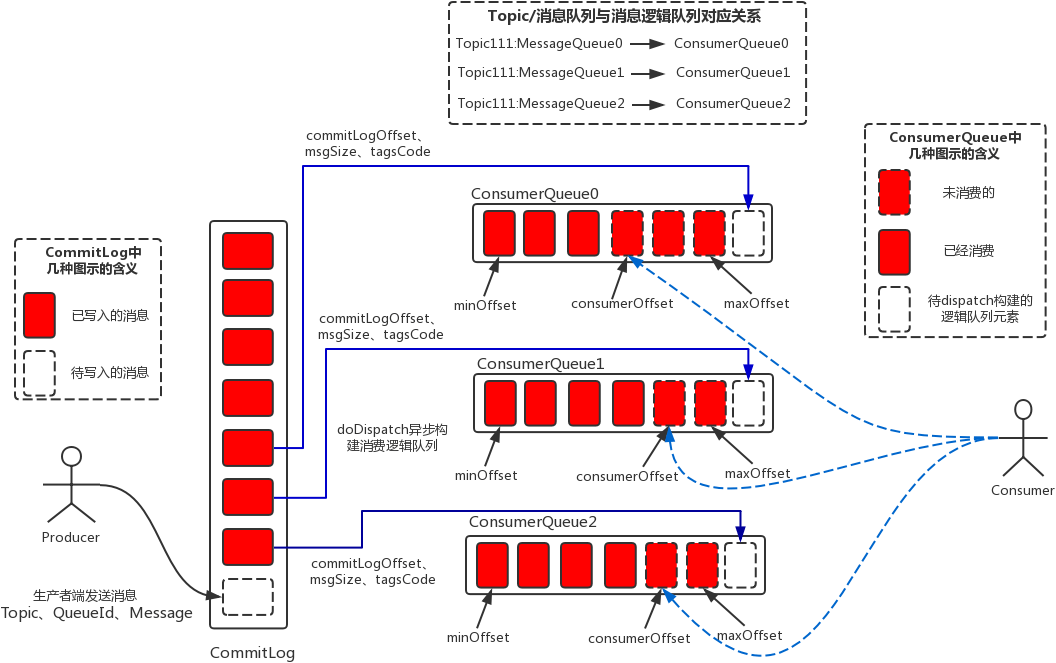
这里有几个概念:
- CommitLog:存储消息主体(虽然名字里有log,但不是日志,它存的是消息数据)
- ConsumerQueue:消息消费队列
- IndexFile:消息索引文件(它跟存储没啥太大关系,是给运维用的)
commitlog
所有producer生产的消息,都会追加写到commitlog里面
注意:这里是谁先到commitlog,谁就先写进去,保证了它是顺序写的
所以可能会出现:前俩消息是 topic1 的,第三个是 topic2 的,第四个是 topic1 的,第五六个是 topic2 的交叉情形
消费队列
由于commitlog并没有做什么优化(比如按照topic分类),所以就有了消费队列
在追加写commitlog的过程中,dispatch线程会按照偏移量一点点往下分发
每来一个消息,它都会根据topic来把消息分发到某个队列里面(注意是某个队列,不是所有队列)
而且一个topic可以对应到多个队列,具体分发给哪个队列则由负载均衡决定(该方案是在producer端做的)
这样一来,消息的写入和消费就会很快,因为它不是由固定队列来承担某个topic的所有消息,而是分摊的
实际消费
队列里存的不是消息实体(如果存消息内容,那commitlog也就没啥意义了)
而是消息的索引(即该消息在commitlog里的偏移量,以及消息实体的大小,和tags)
所以实际消费时就会根据偏移量到commitlog找到消息,然后取出消息内容,接着被消费端消费
随机消费
这里就有一个问题:topic是顺序写的,而消费则不是顺序消费的
即同一个topic连续投递过来的两个顺序消息,可能会被分发到不同的队列,导致消费不一定是连续的
所以会出现topic是顺序写到commitlog的,而消费则是在commitlog的一段范围内随机读的
虽然顺序写随机读这个问题,不如顺序读性能高,但其实影响不是很大(只是在做时间轮时有点影响)
重复消费
它只保证消息不丢,但不保证消息不重复
因为consumer在从消费队列取数据时,不是一条一条取的,而是一次取 N 条,然后去慢慢消费
若这个过程中consumer挂了,那么下次消费时,所取的数据还是会包括这一次的消息
直到consumer显式的回复 ack 给消费队列,消费队列才会去偏移(即移动offset)
所以,如果我们不能接受重复消息,那就得做幂等
优化
如果有优化需求,可以考虑从以下三个角度着手:
- CommitLog文件切分(默认1G)
假设某业务堆积了很多消息,然后它突然开始消费,此时堆积消息可能位于commitlog的中部或顶部
那么就要加载一个很大的文件来读到那些堆积消息(代价有点大),所以做切分,按需加载就行了 - MMap提升文件访问性能
内存文件映射机制,可以认为它做了一次类似于零拷贝,减少了内核态和用户态的切换
其实就是对写入做了一次优化,多次读直接读内存,减少了系统调用 - SSD(就算是普通的机械盘,一般也不会有什么性能问题)