高可用与多写
普通的存储系统(如MySQL),通常要解决 2 个的问题:非高可用、单点写入
高可用
高可用的方法论,其实就两个字:冗余。
即把数据复制几份,冗余到多个地方,就能保证高可用(MySQL的主从集群、磁盘的RAID等就是这个原理)
但数据冗余往往会有 2 个副作用:
- 数据一致性:例如MySQL主从集群,读写会有延时,会有一个短时间内的读写不一致
- 写入的效率:数据冗余往往会降低写入的效率,因为数据同步也是需要消耗资源的
注意:分库分表解决的不是高可用的问题,它解决的是数据量大的问题
多写
普通的存储系统,也可以多点写入,但多写可能引发数据一致性的问题:即写写冲突
例如 MySQL 也可以做一个双主的架构:两个节点可以同时写入
假设某表的主键是自增ID,目前 2 个主节点中的表数据都是 id=1/2/3/4,然后 A 节点写入了一条数据,此时 A.id=5
在 A.id=5 的数据同步到 B 节点的过程中,B 也写入了一条数据,B.id 也会变成 5,于是 B 也向 A 同步数据
当同步数据到达对方后,冲突了,于是同步失败,这就是写写的一致性冲突问题
避免方式就是:不依赖于数据库层面的自增ID,而是由应用层来生成这个ID(简单的场景也可以用不同步长的方法)
MySQL的众多HA方案中,有一种MMM(Multi Master Replication Manager)架构与之类似
大致思路就是:同样有 2 个主节点,但只有一个对外提供服务,另外一个 stand by(且二者在实时的双主同步)
同时,两个主节点使用相同的虚IP(即内网IP是相同的),然后通过类似于 Keepalived 的方式去探活
当发现主库有问题的时候,虚IP自动漂移到备用主库上(即流量打到另外一个主库上),保证了主库的高可用
而整个过程对于应用层是透明的
但这样能否消除数据不一致呢?答案是悲观的:在极限的情况下,仍可能引发数据不一致
这时,可以考虑以内网DNS探测的方式,来做缓解(可理解为双主同步完数据之后,再实施虚IP偏移),步骤如下:
- 使用内网域名连接数据库,例如:db.qss.com
- 主库 1 和主库 2 设置双主同步,不使用相同虚IP,而是分别使用 ip1 和 ip2
- 一开始 db.qss.com 指向 ip1
- 用一个小脚本轮询探测 ip1 主库的连通性
- ip1 主库发生异常时,脚本 delay 一个 x 秒的延时,待主库 2 同步完数据后,再将 db.qss.com 解析到 ip2
- 应用程序以内网域名进行重连,即可自动连接到 ip2 主库,并保证了数据的一致性
本质上,这是一个可用性与一致性的折衷(牺牲了 x 秒的高可用)
当写写发生了一致性冲突时,常见的处理方式有以下 3 种:
- 投票:集群中的多个节点来投票,以多数票的数据为准
- 时间戳:以时间戳最小的数据为准,即最早写入的那一条为准,后写入的放弃
但时间戳也要注意时钟同步的问题(毕竟多进程异步系统中,是没有全局绝对时钟的)
也有一些时钟同步的算法,比如这篇文章:巧妙测量服务器之间的时间差 - ID串行化:多点写入前,去同一个地方领取ID,再各自写入,写入时若发现业务属性冲突,就以最小ID为准
即时通讯中,群消息可以用到这个,能保证每个人看到的消息序列是相同的
而微信/QQ这种群消息,每个人看到的消息序列不同,也没多大问题(技术可以做到,业务未必必需)
区块链
区块链是一个去中心化的(没有中心节点和管理员)、每个节点都拥有全部数据的、高可用的、分布式存储系统
而,区块,就是一块可以存储数据的存储空间
再通过类似链表的方式,将各个区块串联起来,并约定了一系列算法来管理这些数据
这就组成了区块链,所以区块链的本质就是一个多点写入的存储管理系统
(可以说,区块链有两个很大的特点:存储数据少,数据写入慢)
区块的组成
一个区块,由区块头和区块体组成
- 区块体:存储交易数据
- 区块头:存储区块的元数据,如上一个区块的哈希值,本区块生成时的时间戳和随机数等等
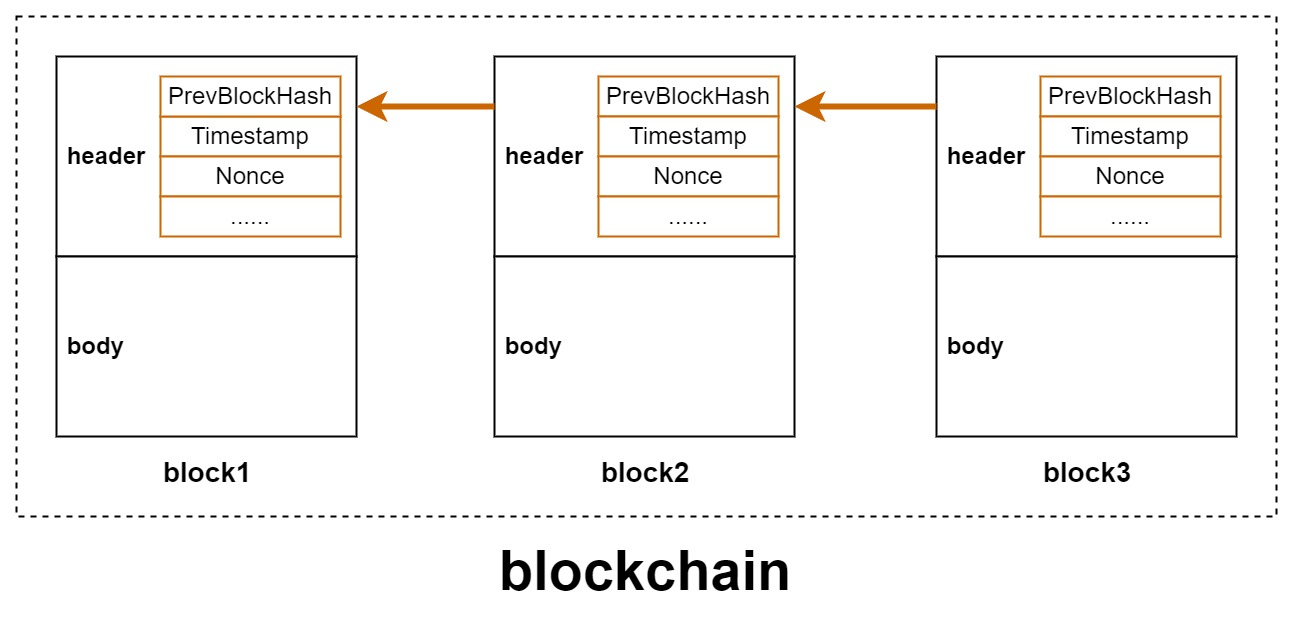
如上图所示,区块头存储了上一个区块的哈希值,本区块生成时的时间戳和随机数等等
一个区块,它的唯一标识就是这个区块的哈希值(好似链表一样,每个链表节点的唯一标识就是它的指针)
于是,通过每个区块的哈希值,将所有的区块链起来(跟链表很像),就组成了区块链
区块的特性
- 历史区块无法改变
- 只能在最新的区块后面,生成新区块(所以必须同步了全网最新的区块,才能启动生成新区块的工作)
- 新区块很难生成,必须满足特定条件
比特币
比特币(BitCoin)就是基于区块链这个分布式存储系统,在其上层实现的一个电子货币的应用
作为电子货币,比特币的业务场景与区块链技术是及其匹配的:
- 高可用:系统永远不会挂
- 去中心:没有人能控制整个系统的运行
- 防篡改:交易一旦写入区块链,则是永久的,是不能够被修改的,所以也不可能存在假币
- 一致性:只要交易确认,最终交易数据一定会达成一致,不可能产生任何纠纷
- 透明性:所有的交易和规则对所有人透明,没有人能够随意发行和隐瞒
因此,市面上除了比特币,还有莱特币、以太坊等等电子货币
貌似至今为止,除了电子货币,好像没有其他非常成熟的上层应用是基于区块链弄的
所以很多人就产生了误解:以为区块链就是比特币,比特币就是区块链,其实完全不是的
比特币与区块链的关系,就好似微信与 MySQL 的关系(MySQL 做底层存储,微信是 MySQL 上层的应用)
挖矿
生成一个区块,并链入区块链的过程,就是挖矿
而挖矿的人,就是矿工
挖到矿(生成新区块)必须满足以下 2 个条件,才算成功:
- 需要对新生成的区块头,进行 2 次 SHA256
- 得到的哈希结果,高 48bit 必须是 0x00000000FFFF
由于每一个区块头都记录了前一个区块的哈希值,所以新区块能变的其实只有时间戳和随机数等等
由于哈希是不可逆的,所以也不能通过哈希结果的高48bit是0x00000000FFFF来反推时间戳和随机数
可以认为哈希的结果是完全随机的,即区块链以及挖矿的一切基础:哈希不可逆性!
要得出前48bit是一个给定的bit,就如同连续抛48次硬币,每次得到的都是想要的结果,这个概率非常非常小
就好比在一座山上随机捡起了一块石头,这块石头又正好是一块金子,概率非常非常小
可能就是因为这个,才称它为挖矿吧,因为一旦成功生成了一块,就等于是捡到了金子
如果逆推不行,唯一使用的方法,就是正向的穷举法,伪代码如下
byte[32] = PrevBlockHash; // 上一个区块的哈希
for(int i=0 to 2^32){ // 遍历所有整数
long time = now(); // 时间戳
blockHeader = new(byte[32], time, i); // 生成区块头
hashResult = SHA256(SHA256(blockHeader)); // 计算哈希值(两次SHA256)
if(hashResult>>208 == 0x00000000FFFF){ // 哈希符合预期
echo "bingo"; // 挖到矿啦
}
}
那么,是不是执行的时间足够久,就一定能挖到矿呢?
并不是!
如果别人的计算能力比你强,在你挖到矿之前,别人先挖到了一个矿,并把他挖到的矿广播到区块链的全链路
此时你本地就不是最新的区块链了,你必须要同步别人先挖到的矿,你才能够在尾部继续挖
所以,你要不断的向网络同步最新的数据,并继续或重新开始挖矿
提升挖矿速度
从架构的角度,通常会考虑以下三种方法:
- 缓存:无效(因为每个区块的哈希值、时间戳、随机值都也不一样,所以无法通过查表的方式来节省时间)
- Scale up:有效(即提升单机能力:增强单 cpu 的计算能力,用 gpu 替代 cpu,用特殊的芯片计算 sha256 等)
- Scale out:有效(即水平扩展:一台机器不行,就搞集群。想跟别人拼算力,往往都是这样来提升本地算力的)
下图就是西藏高原上的一个比特币矿场,它通过风力和太阳能发电,所以电力比较便宜
所有的矿机都是在进行 sha256 计算,尝试同步全球最新的区块数据,并挖到矿

提升系统性能,不管是区块链还是做系统架构,无外乎这 2 个方法:scale up、scale out
一种是提升软件性能,一种是提升硬件性能
软件:比如发现有一个性能瓶颈,那就优化代码(无锁的方式、并发的方式、巧妙的算法、巧妙的数据结构等)
硬件:由于单节点的软件性能的优化一定是有上限的,你是没办法做到无穷的,那么还可以提高单机的硬件性能
但是,单机硬盘、CPU核数、内存也不可能无限大,所以最终想无限性能,理论上还是 scale out 的方式
矿的匀速机制
2008 年中本聪在设计比特币网络时,把每个区块的大小限定在了 1 MB
这也就意味着每个区块里能存储的信息最多也只有 1MB(目前比特币的区块链大小已经超过了 300 GB)
以承载比特币的区块链为例:平均每 10 分钟产出一个区块,这个速度基本上是不变的
也就是说,虽然大家都在挖矿,虽然计算能力越来越强、计算节点越来越多、哈希速度越来越快
但产出矿的速度基本是不变的,是因为这里面有一套动态调节的机制,来保证生成区块的速度是均匀的
- 统计机制:假设期望比特币全球区块链每 10 分钟生成一个区块,故首先需要一个统计机制,比如 2 周做一次统计
如果统计的结果是最近 2 周平均每 5 分钟就生成了一个区块,说明生成的速度太快了,需要变慢 50%
如果统计的结果是最近 2 周平均每 2 0分钟就生成了一个区块,说明生成的速度太慢了,需要加速一倍 - 调节机制:区块链中有一个难度系数来调节生成区块速度的快与慢
难度系数影响的是区块头的哈希结果有多少比特必须符合预期,才算挖矿成功
比如,原计划哈希结果高 48bit 符合预期,才算挖矿成功
现在改为 49bit 符合预期,才算挖矿成功,这时,预期哈希的概率就降低了,整体挖矿的速度就变慢了
相反,若改为 47bit 哈希结果符合预期,才算成功,这样得到预期哈希的概率就变高了,挖矿就变快了
即:区块链匀速生成区块的方式,是通过调节 sha256 哈希生成的结果有多少位符合预期,来做到的
注意:区块链的限速没有人为干预,都是写在程序里面的,如果生成太快了,它会自动的调节区块哈希比对的位数
获取比特币收益
空手套白狼获取比特币的唯一方式就是挖矿
每当矿工挖到矿,会生成一个新的区块,就能够得到相应的区块奖励
这里面有两部分收益:
- 区块补贴:在进行了大量的计算,挖到新的区块时,会一次性奖励若干的比特币,这些比特币是凭空多出来的
- 交易费用:持有比特币的人,如果要进行比特币交易,它的交易转账记录就要写到某个账本上,即写到区块体里
那么该区块所属人就可以收取一笔交易费用,如 0.5 比特币,这些比特币是交易比特币的人给矿工的
在比特币的系统设计里,比特币的单位是:中本聪(Satoshi Nakamoto),它的换算方式如下:
1 BTC = 1000 中
1 中 = 1000 本
1 本 = 100 聪(Satoshi)
而区块补贴,是凭空生成比特币的唯一方式,但它有一个折半规则:
挖出前 21 万个区块,补贴 50 BTC,后续每生成 21 万个区块(大约 4 年),补贴减半
当补贴低于 1 Satoshi 时,区块补贴就会停止发放,这时大约是 2140 年左右
50 + 25 + 12.5 + … = 2100W
即比特币最多发行 2100 万个,它不会像纸币一样通货膨胀,这一切都是区块链底层的程序控制的
区块链的分叉
全球每个区块链的节点都包含全部的数据,大家都在最新区块链数据的基础之上挖符合条件的区块
如果两个节点同时挖到矿,都把自己挖到的节点,链到本地的区块链上,于是就出现了区块链分叉
这时,局部的节点会以为自己在最新链上挖到了矿,并会将挖到矿的信息传播给附近的区块链节点
以便于其它的节点先同步完最新的数据,再在最新的数据基础之上继续挖矿
(此时,大家都以为自己是在最新的节点上的,并继续挖矿)
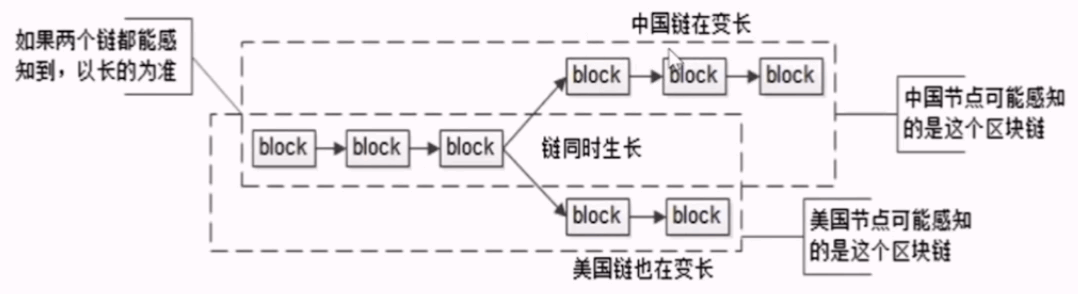
如上图所示:
离中国节点比较近的节点,会同步中国链,并在此链的基础上继续挖,此链会继续增长
离美国节点比较近的节点,可能先同步到美国链,并在此链的基础上继续挖
如果还有一个节点,与中国美国两个链的距离差不多,它又同时收到了这两个冲突的区块链信息
那么它会判断此时哪个链条更长,会以长度更长的区块链为准(即以中国链为准)
因为要挖出更长的区块链,你消耗的算力更多,整体的原则是:不能让绝大部分矿工白干
如此迭代,最终全球的区块链会达成一致,以最长的区块链为准
如果不遵守规则,成为少数派的节点,你继续在少数派的节点上挖,最终不会被多数派承认,等于是白干了
所以在区块链的系统里,遵守规则是所有节点的最佳策略
除非有一个人掌握了全球 51% 的算力,他才能够为所欲为,但这不就相当于中心化了吗
变成了有一个中心化的节点了,它可以控制整个数据的走向
以承载比特币应用的区块链为例:一般我们认为 1 个区块后面链了 6 个区块后,就不可能被颠覆了
故基于比特币的区块链,一般生成新的区块,需要 6 次确认
所以,对于一个矿工来说,挖到一个新的区块,别高兴的太早,等后面生成了 6 个其它的区块
进行了 6 次确认之后,基本上才可以认为你生成的这个区块成功了
(承载比特币的区块链平均每 10 分钟生成一个区块,6 次确认大概需要 1 个小时)
软分叉
当区块链系统升级后,所有的节点的升级节奏其实是不一样的
在所有节点升级到最新的版本之前,由于程序版本的差异可能导致分叉
只要升级到最新的版本,分叉就会消失,这就是软分叉
也就是说,软分叉其实是临时的,等大家的软件版本都升级上来,软分叉就会自动消失
硬分叉
有一些节点玩家头硬,他就是不按照规则来,拉了一个分支
以道德或者法律的名义说我这个分支为准,号召区块链玩家承认自己的链,这样就会形成永久的分叉,即硬分叉
历史上最出名的硬分叉,要属以太经典(ETC)和以太坊(ETH)的分叉
事件起因是:有黑客利用技术手段盗取了大概 6000W 美元的合约币
以太坊开发团队修改了源代码
强行的把 192W 个区块的资金转移到另外一个地址(到另外一个区块上),以夺回黑客控制的合约币
绝大部分的矿工认同了这个修改(觉得这个黑客把币盗走了不行,所以就认同了这个强行修改源码的硬分叉)
一部分矿工不认同这个修改,于是最终就形成了两条链,新的链是以太坊,原来的链路就是以太经典
大家都在自己的认可的链路上继续挖矿
所以,硬分叉其实本质上违背了区块链不能修改的技术本质,采用人为的手段强行回滚
虽然,理论上任何人都可以修改程序,升级版本,你挖你自己的,但就看有没有人陪你玩了
如果你挖到的矿大家都不认可,那就纯属浪费电了
还是那句话,在区块链的世界里,遵守规则才能让矿工的利益最大化
关于分叉,总结起来就是:
- 区块链分叉,本质是一个 “ 高可用存储,数据一致性 ” 的问题(临时出现了数据不一致,但最终会达成一致)
- 探测到分叉时,会以更长的链为准(不能让绝大部分矿工白干)
- 软分叉,本质是软件版本不一致导致的分叉,当软版本一致时,软分叉会消失
- 硬分叉,本质是 “ 强制回滚 ”
- 在区块链的世界里, “ 遵守规则 ” 是最佳策略