简述
它一种无侵入的分布式事务解决方案,属于 2PC 的广义实现,其源自阿里云 GTS 的 AT 模式的开源版
其核心价值在于
- 低成本:编程模型不变(原来怎么写还怎么写),轻依赖,不需要为分布式事务场景做特定设计(没有各种补偿)
- 高性能:一阶段提交(本地提交,全局没提交),不阻塞,连接释放,保证整个系统的吞吐
注:这是比较难的地方,要想保证隔离性,就不能本地提交,这样性能就有衰减
虽然 XA 能保证隔离性,但是在没提交的情况下,资源都是被它锁住的,自然性能就不行 - 高可用:极端的异常情况下,可以暂停或跳过异常事务,保证系统可用
注:这就是一个柔性的问题了。比如说微服务设计时,也讲柔性,叫柔性可用
最常见的例子就是熔断降级,很多请求实在处理不了了,可以把它丢弃掉,要保证系统的整体可用
全局锁
这里有两个概念:镜像和全局锁,镜像在下文中有介绍,这里提前说下全局锁
Seata中的分布式事务,都有各自的 XID,每个 XID 都会把 “行锁”(也叫全局锁)注册到 TC 里面
注意加了引号,它不是数据库的那个行锁,它是把分支事务数据库中的数据的主键的某个值注册到 TC,它是全局的
这是 Seata 自己实现的,保证了先拿到全局锁的全局事务做完了所有事之后,其它全局事务才能提交本地事务
并且,高并发下它也不会出现死锁,只是会有等待,性能有点衰减
那么新问题来了:比如商品增加库存,它不是一个分布式事务,既然没有分布式事务去管理它,那就不会被全局锁锁住
于是 AT 还支持管理这种单次操作(加一个注解),让它也注册到 AT(虽然不是分布式事务,但可以使用里面的锁)
所以它在操作库存时,也会到 TC 里找所要操作的记录是否被锁住,这就搞定了隔离性
不会出现下单操作还没回滚呢,库存就被修改了,这就保证了不会脏写
但有个前提:若不检查(比如某业务未注册到 TC 或人为修改数据库)全局锁(注册到 TC 上的锁),那锁就失效了没意义了
隔离性
先看一下四种隔离级别:
- Read Uncommitted(读未提交):最低隔离级别,会读取到其他事务未提交的数据
即其他事务update操作commit之前,它就能读到update之后的结果,若最后update回滚了,那它又读到之前的结果 - Read Committed(读已提交):事务过程中可以读取到其他事务已提交的数据
这是Oracle默认隔离级别,即只要其他事务未commit,那读到的都是之前的结果,只有commit后读到的才是新结果 - Repeatable Read(可重复读):每次读取相同结果集,不管其他事务是否提交
这是MySQL默认隔离级别,是依赖MVCC(Multi-Version Concurrent Control,多版本并发控制)实现的快照读
比如MySQL的记录中,会有两个隐藏列(版本号和回滚指针),回滚指针指向undolog中的上一次修改的记录
上一次的记录中可能又有回滚指针指向再上一次的记录,故无论怎么修改,都能从undolog中读到当时select的数据 - Serializable(可串行化):事务排队,隔离级别最高,性能最差,也是最严格的隔离级别
写隔离
- 一阶段本地事务提交前,需要确保先拿到全局锁
- 拿不到全局锁,不能提交本地事务
- 拿全局锁的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁
比如俩人都要买 gid=100 的商品,那这俩全局事务都会先去获取本地锁(gid=100,也就是数据库的行锁),先拿到者先减库存
减完库存就要提交本地事务,这时就会去拿全局锁(为了保证只有他一个全局事务在操作gid=100),拿到之后提交本地事务
接着,等待购买的另一个人,这时才会拿到他的本地锁,去减库存,去提交本地事务,然后也去拿全局锁
如果拿全局锁超时,那就回滚本地事务,释放本地锁
下面这个图比较直观一些
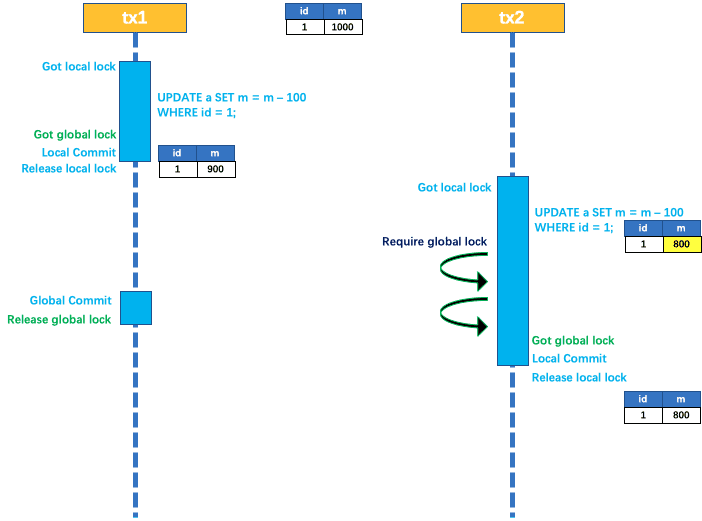
两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新,m 的初始值为 1000,两个事务同时启动
tx1 先拿到本地锁(tx2 只能等待),更新 m = 1000 - 100 = 900。tx1 提交本地事务前,去拿全局锁,接着本地提交释放本地锁
这个时候,tx2 才能拿到本地锁,更新 m = 900 - 100 = 800。tx2 的本地事务提交前,同样会去拿该记录的全局锁
由于 tx1 全局提交前,该记录的全局锁被 tx1 持有,故 tx2 需要重试等待全局锁
等到 tx1 二阶段全局提交后,释放全局锁。此时 tx2 才能拿到全局锁,于是提交本地事务并释放本地锁,最终 m 成功更新为 800
如果 tx1 二阶段回滚怎么办,来看下面的图
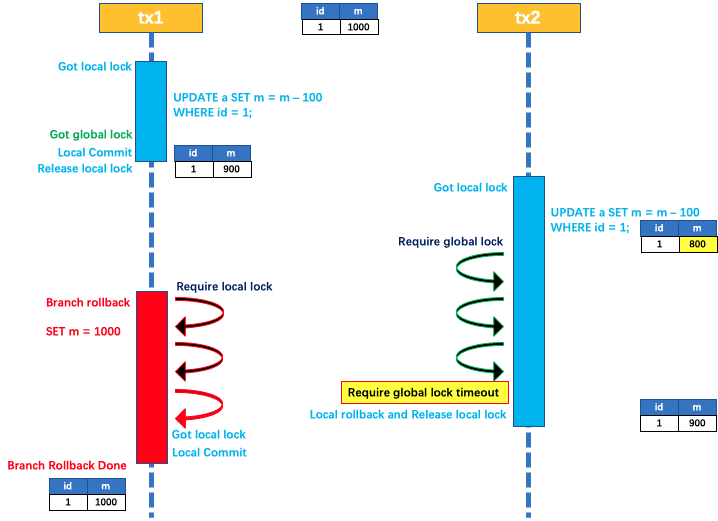
tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚
此时由于 tx2 仍在等待该数据的全局锁,同时也持有本地锁,故 tx1 的分支回滚会失败,然后会一直重试
直到 tx2 的全局锁等锁超时,放弃全局锁并回滚本地事务释放本地锁,然后 tx1 的分支回滚最终成功
由于整个过程全局锁在 tx1 结束前一直是被 tx1 持有的,所以不会发生脏写的问题
读隔离
在数据库本地事务隔离级别为 读已提交或以上 的基础上,AT 模式的默认全局隔离级别是读未提交
如果要求全局读已提交,那就要用 SELECT FOR UPDATE 语句来拿全局锁
Seata检测到 FOR UPDATE 后缀时,就会去申请全局锁,如果全局锁被其他事务持有,则释放本地锁并重试
这个过程中,查询是被 block 住的,直到全局锁拿到,即读取的相关数据是 已提交 的,才返回
如下图所示
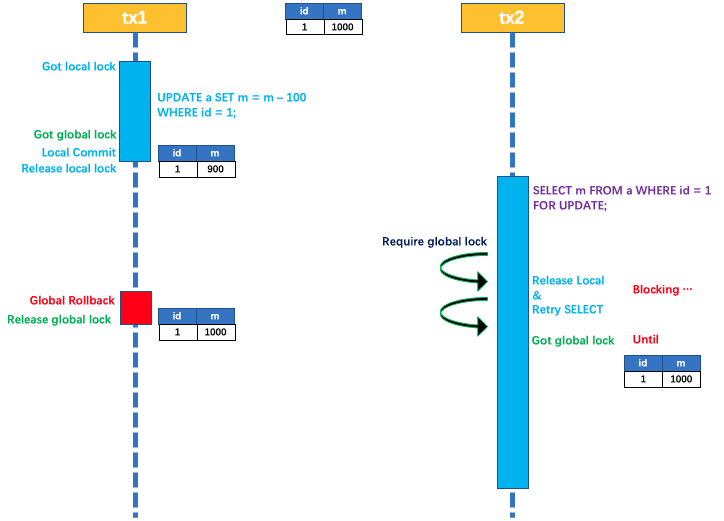
注:出于总体性能的考虑,Seata 目前的方案并未对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT
另外,如果要求全局可重复读,则至少要保存近期的undolog,不能用完一个删一个,期待后面会有这个功能
工作机制
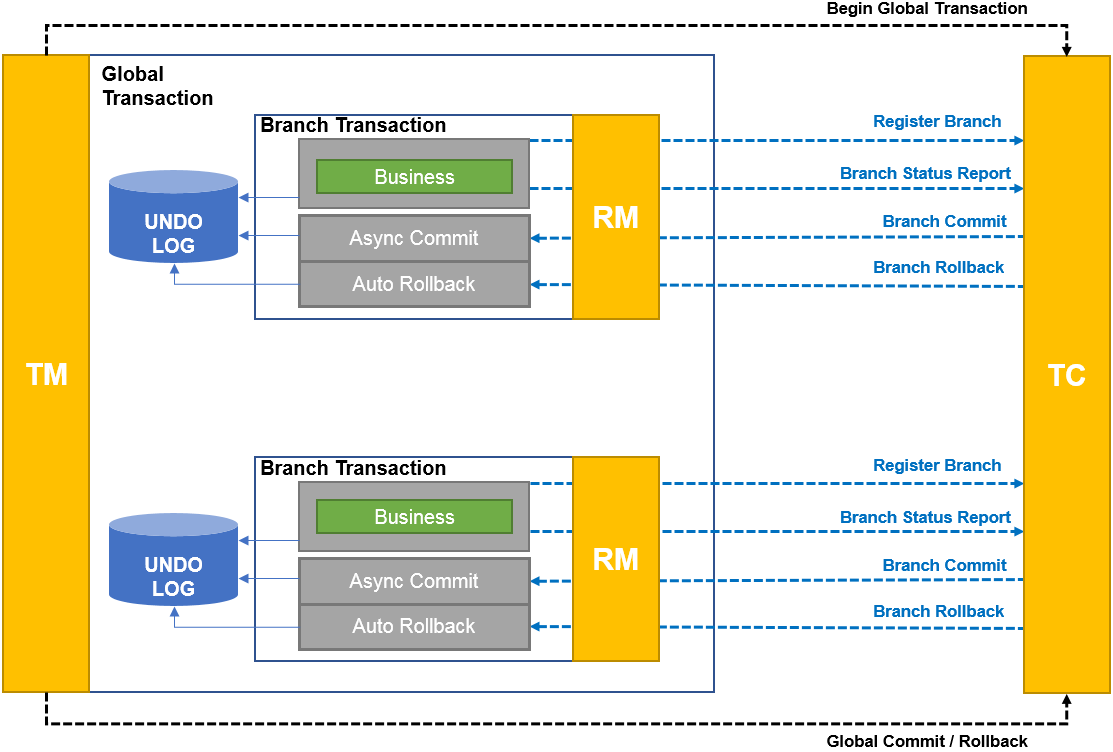
AT 模式 RM 驱动分支事务的行为,分以下两个阶段(这句话很重要)
- 一阶段解析SQL并生成前后镜像提交本地事务
- 二阶段则是 TC 向所有 RM 发起提交或回滚
前后镜像的好处是:如果没有他们,那后面回滚时,就需要业务来做补偿,就做不到无侵入了
并且有了补偿就一定要考虑补偿的幂等(并且不是所有的业务都支持补偿时候的幂等),还要处理空补偿、防悬挂的问题
下面以用户下单减商品库存为例(商品编号gid=100,库存数count=10),详细介绍两个阶段干的事
一阶段
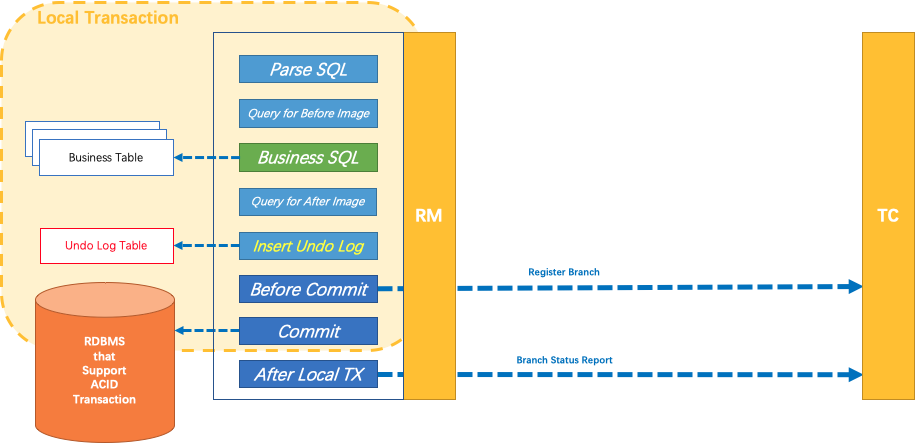
现在要减一个库存,即:UPDATE goods SET count=count-1 WHERE gid=100
- 解析SQL:可认为 RM 封装了 DataSource,这里会得到SQL类型(UPDATE),表(goods),条件(where gid=100)等信息
- 生成前镜像:比如SQL是 update * where,那记录时把 UPDATE 改成 SELECT 就得到了前镜像的结果集(相当于备份数据)
- 执行业务SQL
- 生成后镜像:同样,再 SELECT 一下记录起来,此时count=9(也是在备份数据,因为分支事务SQL执行完是会本地提交的)
- 记录undolog:undolog 在 mysql 里面是用来做回滚的,这里实际就是将前后镜像组合,然后用 json 存到 UNDO_LOG 表中
- 提交前,向TC注册分支:这里会申请 goods 表中主键值等于 100 的记录的全局锁
- 提交本地事务:业务数据的更新和前面生成的 undolog 一并提交
- 将本地事务提交的结果上报给 TC
用户下单减库存时,每次下单操作都是一个独立的分布式事务,各自有不同的 XID
此时隔离性是能够保证的(即其它 XID 不会染指到这条数据),因为每个 XID 都会到 TC 里面注册全局锁
二阶段(提交)
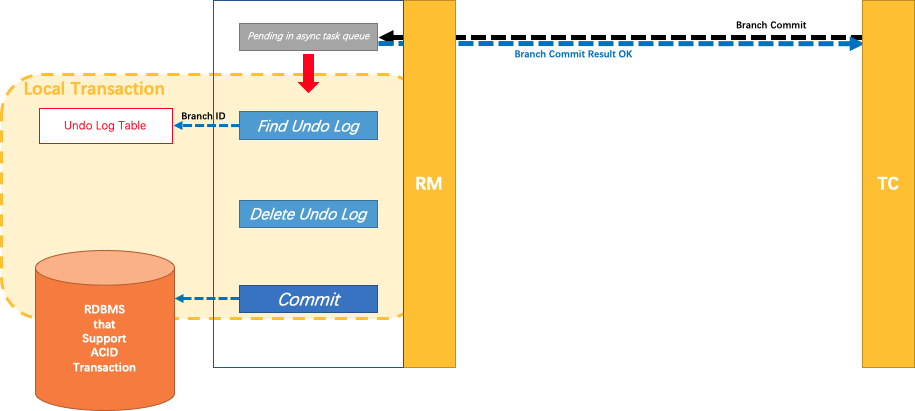
- TM 向 TC 发起全局提交
- TC 向 RM 发起分支提交(传递XID)
- RM 将请求放入一个异步任务的队列中,并马上返回提交成功的结果给 TC
- 异步任务阶段的分支提交请求将异步和批量地删除相应 undolog
二阶段(回滚)
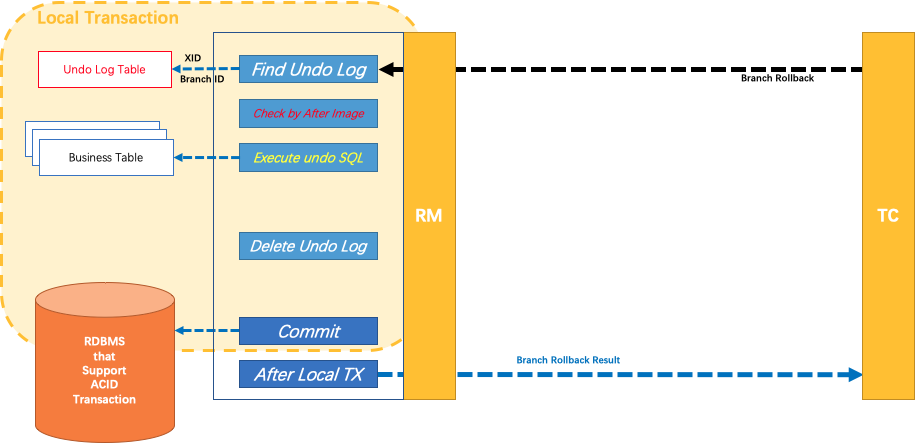
- 收到 TC 的分支回滚请求,开启一个本地事务
- 通过 XID 和 Branch ID 找到相应的 undolog
- 校验脏写:后镜像与当前数据库数据比较,如有不同则说明已被当前全局事务外的动作做了修改,此时需根据配置策略来处理
- 还原数据:根据前后镜像,生成逆向SQL并“回滚”(相当于重新写入一次)
- 删除undolog
- 提交本地事务,并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC
AT存在的问题
- 重量级SDK
- 依赖数据库本地事务的 ACID 特性
- 如果用的是mongodb或其他的KV存储,AT 搞不定,所以 Seata 又搞了TCC、Saga
这里 Saga 是不加锁的,事务直接就提交了,也没有全局锁控制,故性能衰减比较弱,但业务侵入大