传统TCC模式
- Try:预留资源(比如转账时,先冻结资金)
- Confirm:使用Try阶段资源
- Cancel:释放Try阶段资源
此时业务服务需要实现以上三个接口,虽然第一步 Try 锁定了资源,减少了失败的可能
但后面 CC 阶段,若两个分支事务有一个失败了(网络原因、系统原因),那业务还要去做主动重试等工作
所以 TCC 如果全交给业务来做,可能还不如业务分别调用一个RPC,每个RPC负责完成自己业务,反倒简单
因为业务逻辑简单,那出错的概率也就更小
所以 TCC 作为一个理论上的模型,真正交给业务去做的话,落地时需要注意的细节还是不少的
SeataTCC模式
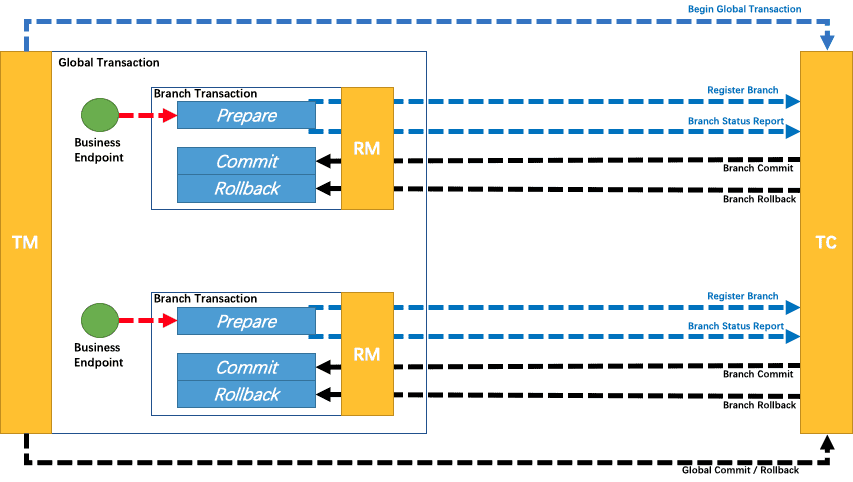
与 AT 模式类似,还是在 RM 过程实现 TCC 三个接口,大体流程如下
- Try 执行前注册分支事务到 TC
- Try 执行完上报事务状态给 TC(告诉 TC,我 Try 成功了)
- 最后还是由 TC 来调度,执行 Confirm 或 Cancel
传统 TCC 模式中,业务还要处理调度的事,而在 Seata 里面,它就管控了整个事务,业务只需要主动调 Try 就可以
CC 调用的事(包括重试)都由 TC 帮我们做了(当然,前提还是 TM 来发起全局事务和提交或回滚全局事务到 TC)
如此,在业务使用上就比较友好了,这都得益于 Seata 的 TM-RM-TC 模型
实现原理
有一个 TCC 拦截器,它会封装 Confirm 和 Cancel 方法作为资源(用于后面 TC 来 commit 或 rollback 操作)
封装完,它会本地缓存到 RM (缓存的是方法的描述信息),可以简单认为是放到一个 Map 里面
当 TC 想调用的时候,就可以从 Map 里找到这个方法,用反射调用就可以了
另外,RM 不光是注册分支事务(分支事务是注册到 TC 里的 GlobalSession 中的)
它还会把刚才封装的资源里的重要属性(事务ID、归属的事务组等)以资源的形式注册到 TC 中的 RpcContext
这样,TC 就知道当前全局事务都有哪些分支事务了(这都是分支事务初始化阶段做的事情)
举个例子:RpcContext里面有资源 123,但是 GlobalSession 里只有分支事务 12
于是 TC 就知道分支事务 3 的资源已经注册进来了,但是分支事务 3 还没注册进来
这时若 TM 告诉 TC 提交或回滚,那 GlobalSession 就会通过 RpcContext 找到 1 和 2 的分支事务的位置(比如该调用哪个方法)
当 RM 收到提交或回滚后,就会通过自己的本地缓存找到对应方法,最后通过反射或其他机制去调用真正的 Confirm 或 Cancel
空回滚
- 场景:Try 未执行,Cancel 执行了
- 原因:Try超时(丢包)了
- 解决:当 TC 发现少了一个 Try,那它就会回滚整个分布式事务,于是触发了 Cancel
直接 Cancel 可能出现数据一致性问题,所以就要记录 Try 是否执行,没执行就要做空回滚(啥都不做直接返回成功)
防悬挂
- 场景:Cancel 比 Try 先执行
- 原因:Try超时(阻塞)了
- 解决:当 TC 发现少了一个 Try,那它就会回滚整个分布式事务,于是触发了 Cancel
然后拥堵的 Try 在 Cancel 处理完(空回滚)又来了,这时同样要记录下整个状态,要拒绝空回滚以后的 Try
幂等控制
- 现象:超时重试、补偿都会导致 TCC 服务的 Try、Confirm 或 Cancel 操作被重复执行
- 解决:Confirm 和 Cancel 开发时要考虑幂等控制(这是必须要做的)
传统Saga模式
其源于 1987 Paper Sagas 论文,它解决的是处理长活事务(long lived transaction)的问题
它将分布式事务拆分成若干个本地事务,每个本地事务都有执行模块和补偿模块
这里面有一个事务管理器,执行模块执行之前要先注册本地事务到事务管理器
如果后面事务管理器没有收到 commit 或 rollback,那事务管理器还要进行超时事务的处理(即调用补偿模块)
而由于执行模块是先注册后执行,但到底有没有执行,这是不一定的(有可能没执行,有可能执行了但还没执行完)
所以它对补偿的要求就非常严格(它不像 AT 那样有一个全局锁,它的每个子事务提交后,还允许其它业务来修改)
还有一个问题:比如有 1234 四个本地事务,其中 12 注册进来了,34 没有注册到事务管理器
那就只能执行 12 的补偿,这就是向后恢复(调用各自补偿接口恢复到事务前)和向前恢复(调 34 的正向接口让事务最终成功)的问题
因为它是柔性事务,它关心的是最终一致性
如果想做向后恢复,就要记录事务执行链路(这样就能知道都需要调用谁的补偿接口去恢复数据)
如果想做向前恢复,就要了解整个全局事务(要想办法知道总共有哪些分支事务,这在传统 Saga 模型是很难做到的,它就只能回滚了)
SeataSaga模式

还是 Seata 标准的框架:在每个 RM 模块中(也就是每个子事务),业务还是实现提交和补偿接口
其流程如下:
- TM 向 TC 发起全局事务
- 每个分支事务注册到 TC
- 执行业务(提交逻辑)并提交 “本地事务”(打引号是因为它不一定是本地事务,也可能是 RPC 调用)
- 上报事务状态给 TC
- 各分支事务提交就提交了,TC 不用管全局提交,只有需要回滚时,TC 才会调用各子事务的补偿接口
也就是说,每个事务参与者提交本地事务,并且,一阶段(提交逻辑)和补偿由业务开发来实现
另外,它是基于状态机引擎控制事务流转的(这个 “事务” 就未必是数据库的事务了,我们确保的是RPC调用的原子性)
状态机引擎原理如下:
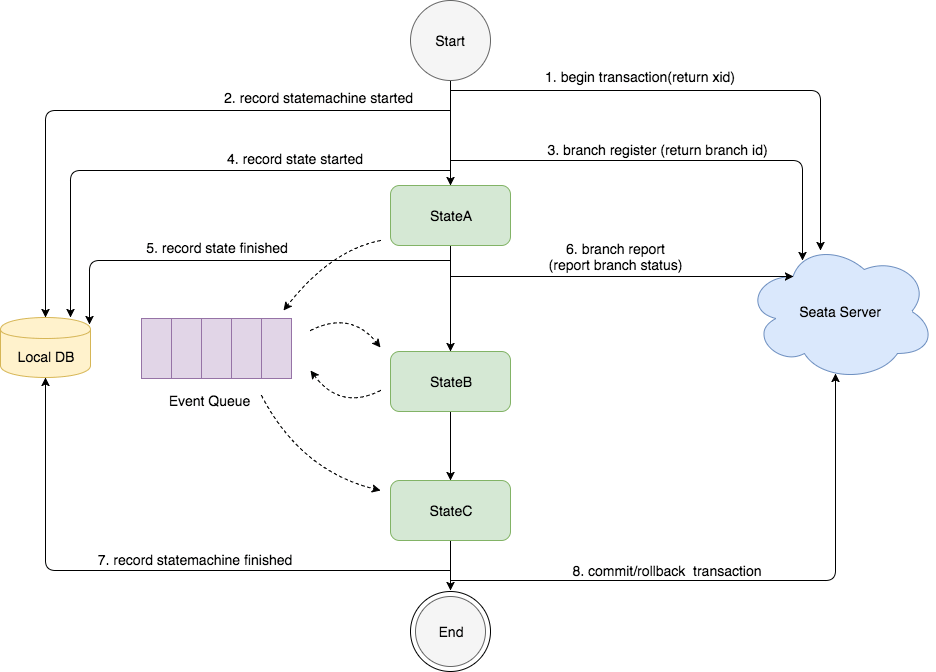
状态机启动时,先向 TM 注册(这样 TM 就能告诉 TC,我开启了一个全局事务),然后它会调 RM(RM 就会注册分支事务到 TC)
然后它会去做 RPC 调用(提交逻辑,成功或失败,接着 RM 就会上报状态给 TC,失败的话就会触发 TC 发起补偿)
这样就完成了一个分支事务的处理,下面再处理第二个分支事务(同样调 RM,调 RPC)
其基本原理就是基于状态图生成状态语言定义文件,每个状态节点配置补偿节点,并由状态机引擎驱动执行
状态机引擎是基于事件驱动的架构,每个节点都可以异步执行,极大提高吞吐量,其事务日志存到与业务系统相同的数据库,提高性能
状态机高可用
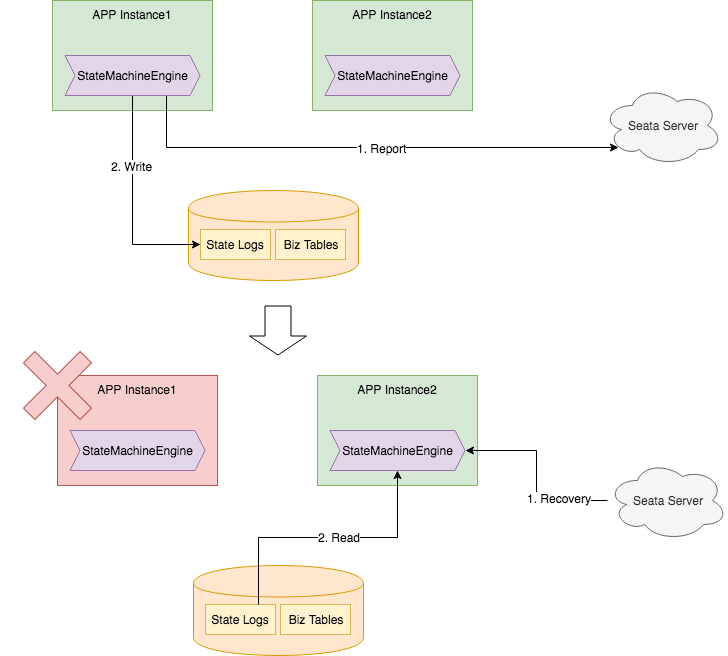
- 应用正常运行时:
- 状态机引擎是无状态的,它是内嵌在应用中(继承在业务模块里)
- 状态机引擎会上报状态到 TC
- 状态机日志会写入到本地数据库
- 应用实例宕机时:
- TC 会发送事务恢复请求到还存活的应用实例(该实例与宕机的实例是干一样事的,它俩相当于负载均衡部署的)
- 该实例会装载数据库日志(记录了状态机执行位置和步骤)恢复状态机上下文继续执行(传统 Saga 模型就只能调回滚了)
所以通过状态机的实现,提高了异常处理的灵活性,可以实现事后恢复(向前重试或向后补偿)
缺点就是要改造现有业务,对业务侵入性比较高,并且状态机引擎的实现成本也不低
补充
Seata 的 Saga 是用状态机实现的,但他的状态机有点重(复杂,看着就累)
如果是自己玩,还是用拦截器实现要好一点
即在执行模块打一个切面,调用前先注册本地事务到 TC,再去调执行模块,这样 TC 就知道谁谁谁了,一般都是这个路子